Hey ML, what can you do for me?
 Abstract
Machine learning (ML) algorithms are data-driven and
given a goal task and a prior experience dataset relevant to the task, one can attempt to solve the task using ML seeking to achieve high accuracy.
There is usually a big gap in the understanding between an ML experts and the dataset providers due to limited expertise in cross disciplines.
Narrowing down a suitable set of problems to solve using ML is possibly the most ambiguous yet important agenda for data providers to consider before initiating collaborations with ML experts.
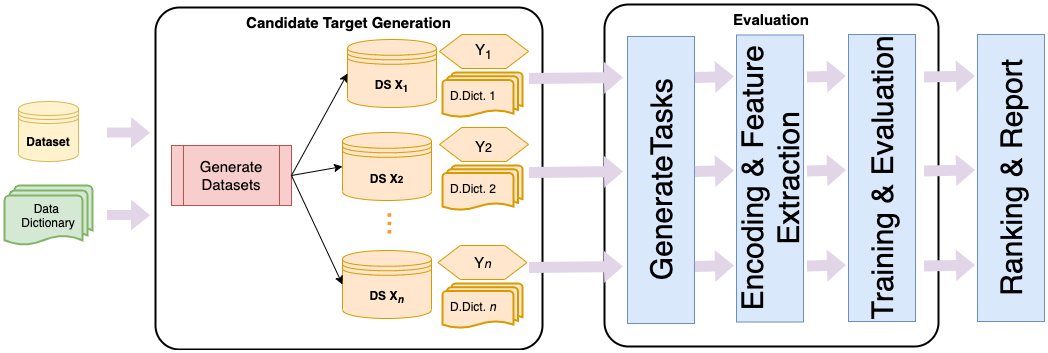
We proposed an ML-fueled pipeline to identify potential problems (i.e., the tasks) so data providers can, with ease, explore potential problem areas to investigate with ML. The autonomous pipeline integrates information theory and graph-based unsupervised learning paradigms in order to generate a ranked retrieval of top-$k$ problems for the given dataset for a successful ML based collaboration.
We conducted experiments on diverse real-world and well-known datasets, and from a supervised learning standpoint, the proposed pipeline achieved $72\%$ top-$5$ task retrieval accuracy on an average, which surpasses the retrieval performance for the same paradigm using the popular exploratory data analysis tools.
Abstract
Machine learning (ML) algorithms are data-driven and
given a goal task and a prior experience dataset relevant to the task, one can attempt to solve the task using ML seeking to achieve high accuracy.
There is usually a big gap in the understanding between an ML experts and the dataset providers due to limited expertise in cross disciplines.
Narrowing down a suitable set of problems to solve using ML is possibly the most ambiguous yet important agenda for data providers to consider before initiating collaborations with ML experts.
We proposed an ML-fueled pipeline to identify potential problems (i.e., the tasks) so data providers can, with ease, explore potential problem areas to investigate with ML. The autonomous pipeline integrates information theory and graph-based unsupervised learning paradigms in order to generate a ranked retrieval of top-$k$ problems for the given dataset for a successful ML based collaboration.
We conducted experiments on diverse real-world and well-known datasets, and from a supervised learning standpoint, the proposed pipeline achieved $72\%$ top-$5$ task retrieval accuracy on an average, which surpasses the retrieval performance for the same paradigm using the popular exploratory data analysis tools.
Source Codes
- Detailed experiment results with our source codes are available here.
Collaborators
- Javier Pastorino
- Ashis Kumer Biswas
News / Achievements
- IEEE AIKE 2020 - Accepted as full paper, presented and published in the proceedings of the 2020 IEEE Fourth International Conference on Artificial Intelligence and Knowledge Engineering (AIKE). Details of the paper.